
If you’re reading this, chances are you’re either (a) secretly googling “Is 30’s too late to start data science?” or (b) sipping chai/coffee while wondering why your Excel pivot tables don’t make you a data scientist yet.
Well, let me reassure you: 30’s is not “too late.” In fact, it’s the perfect age. You’ve got wisdom from experience, just enough energy to pull late-night coding sessions, and maybe even a sense of humor to laugh at Python’s cryptic errors. Trust me, that’s half the battle—and I’ve been there.
The field is booming, and honestly, with a little patience, structure, and humor, you can go from “what even is Python?” to “training deep learning models” faster than you think.
Why I Chose Data Science
Coming from a background in engineering and teaching, I always enjoyed working with logic, numbers, and problem-solving. But with the industry moving fast toward data-driven solutions, I wanted to upgrade my skills in a way that opened up new career opportunities. Data science felt like the right blend of analytics, coding, and creativity.
When I decided to step into the world of Data Science in my 30s, I was both excited and overwhelmed. There are endless tutorials, courses, bootcamps, and gurus telling you “the right way.”
So, instead of sinking in that quicksand, I built my own structured plan—a roadmap that balances theory, tools, and sanity.
📌 This is the roadmap I followed:
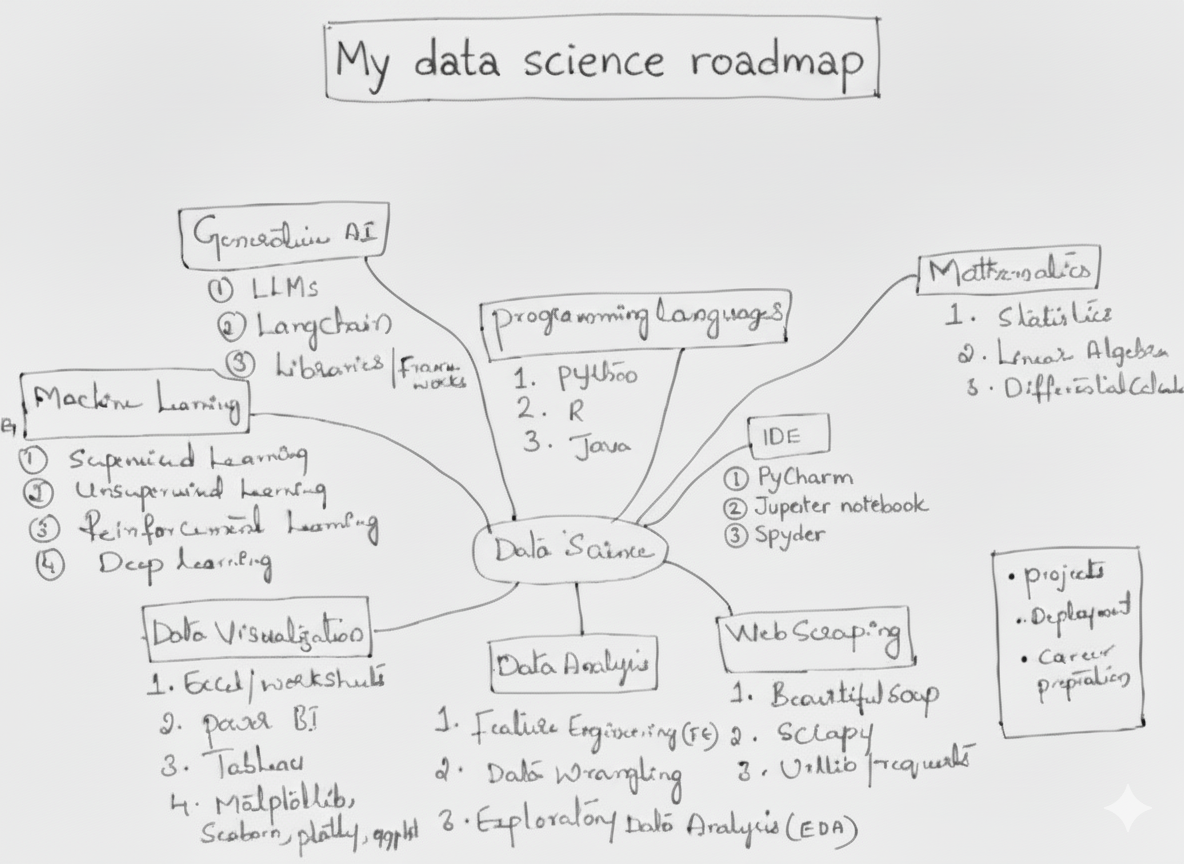
I’m still on my own journey of learning Data Science, and while exploring different courses and projects, I created this roadmap to keep myself consistent and clear about what to learn next. It’s a structured plan I personally follow — and I’m sharing it here for anyone who’s walking the same path and wants a clear direction to begin.
1. Programming Languages & Tools (Foundation)
Start with Python—it will cover 90% of your needs. Learn how to manipulate data with Pandas, NumPy, and move into visualization. Later, you can explore R (great for statistics), or even Java/JavaScript for specific domains.
👉 Pick one language and master it deeply. Python is your best bet.
Also, get comfortable with IDEs: Jupyter (for exploration), PyCharm or VS Code (for larger projects).
2. Data Handling & Processing
This is where most beginners underestimate the effort. But trust me—70% of a data scientist’s job is here.
- Data Wrangling: Fix missing values, duplicates, outliers.
- Feature Engineering (FE): Turn raw data into meaningful inputs.
- Web Scraping: Learn Beautiful Soup, Scrapy, or APIs to collect data.
- EDA (Exploratory Data Analysis): Use Pandas + Seaborn to discover trends and hidden patterns.
3. Data Visualization & Communication
Data is useless unless you can explain it. Learn:
- Excel/Worksheets (for quick pivot analysis)
- Power BI or Tableau (to create dashboards for managers)
- Matplotlib, Seaborn, Plotly, ggplot (to visualize insights in Python)
👉 Visualization isn’t about “pretty charts.” It’s about telling a story with data.
4. Mathematics for Data Science
Don’t get scared here—you don’t need a PhD in Math. Focus on what connects directly to ML:
- Statistics: Probability, hypothesis testing, distributions.
- Linear Algebra: Vectors, matrices (the backbone of ML).
- Calculus: Basics of differentiation, mainly for optimization.
💡 You don’t need to be Ramanujan. You just need the math that makes models click.
5. Machine Learning & AI
Here comes the exciting part! Start with classical ML before jumping into Deep Learning.
- Supervised ML: Classification, Regression.
- Unsupervised ML: Clustering, Dimensionality Reduction (PCA, t-SNE).
- Reinforcement Learning: For decision-making problems.
- Deep Learning: CNNs, RNNs, Transformers.
- Generative AI: LLMs (ChatGPT, Hugging Face), LangChain.
👉 Use libraries like Scikit-learn, TensorFlow, PyTorch. Theory + practice is the key.
6. Projects, Deployment & Career Prep
This is the most underrated block, but it’s where careers are made.
- Projects: Start with Kaggle datasets, then build end-to-end pipelines (data collection → cleaning → model → deployment).
- Deployment: Learn Flask, FastAPI, or Streamlit to showcase your models.
- MLOps: Docker, MLflow, and cloud basics (AWS/GCP/Azure).
- Career Prep: Build a GitHub portfolio, update LinkedIn, tailor your resume to highlight projects, and practice case studies.
👉 Certificates are fine, but projects speak louder. Your portfolio is your golden ticket.
My Learning Journey: From Online to Offline
Like many beginners, I started with online resources:
- Krish Naik (YouTube)
- CampusX: 100 Days of ML
- AI tools (to simplify doubts)
- Tutorials in my own language
This gave me a foundation, and I even completed the IBM Data Science Professional Certificate.
But then, reality hit: online learning can feel lonely. So, I joined a Diploma in Data Science (offline), where I found:
- A community of learners
- Mentorship and guidance
- Accountability and consistency
Tips for Fellow Learners in Their 30s
- Don’t wait to “learn everything” before starting projects.
- Mix online flexibility with offline accountability.
- Read research papers.
- Build a portfolio—small but consistent.
- Stay curious and patient; this is a marathon.
Final Words ✨
Switching to data science in your 30s isn’t reckless—it’s realistic. I’m still learning, still experimenting, still failing (sometimes gloriously). But with this roadmap and structured approach, I’ve managed to turn a vague interest into a clear path.
So, if you’re in your 30s and wondering if it’s too late, here’s the truth: it’s not. In fact, it might just be the perfect time.
✨ That’s my structured plan. Now it’s your turn—what’s stopping you from starting? ✨
at’s stopping you from starting? ✨ ✨ That’s my structured plan. Now it’s your turn—what’s stopping you from starting? ✨